Recent video diffusion models have enhanced video editing, but it remains challenging to handle instructional editing and diverse tasks (e.g., adding, removing, changing) within a unified framework. In this paper, we introduce VEGGIE, a Video Editor with Grounded Generation from Instructions, a simple end-to-end framework that unifies video concept editing, grounding, and reasoning based on diverse user instructions. Specifically, given a video and text query, VEGGIE first utilizes an MLLM to interpret user intentions in instructions and ground them to the video contexts, generating frame-specific grounded task queries for pixel-space responses. A diffusion model then renders these plans and generates edited videos that align with user intent. To support diverse tasks and complex instructions, we employ a curriculum learning strategy: first aligning the MLLM and video diffusion model with large-scale instructional image editing data, followed by end-to-end fine-tuning on high-quality multitask video data. Additionally, we introduce a novel data synthesis pipeline to generate paired instructional video editing data for model training. It transforms static image data into diverse, high-quality video editing samples by leveraging Image-to-Video models to inject dynamics. VEGGIE shows strong performance in instructional video editing with different editing skills, outperforming the best instructional baseline as a versatile model, while other models struggle with multi-tasking. VEGGIE also excels in video object grounding and reasoning segmentation, where other baselines fail. We further reveal how the multiple tasks help each other and highlight promising applications like zero-shot multimodal instructional and in-context video editing.
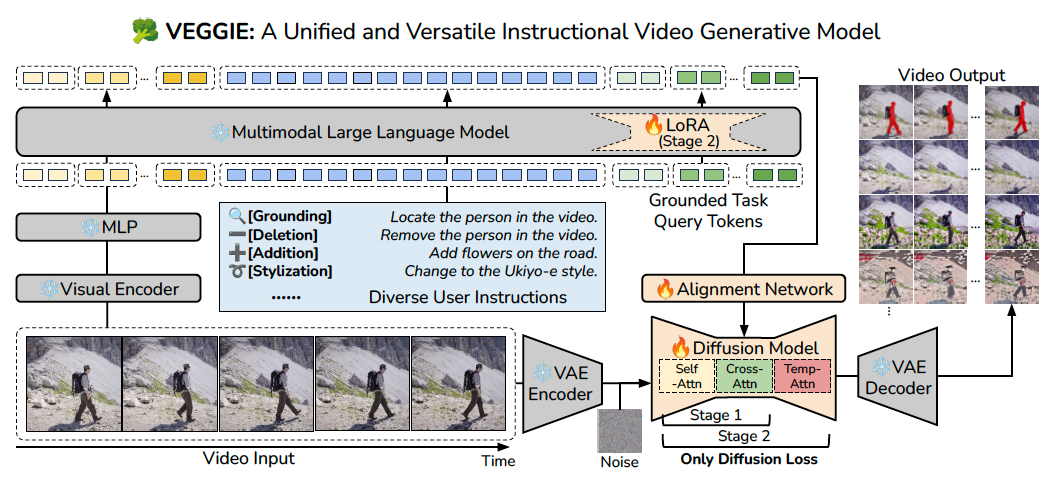
Figure2: Overview of our proposed end-to-end VEGGIE framework. Our Multimodal Large Language Model first understands input video frames and diverse user instructions, then it generates frame-wise reasoning queries that maintain per-frame editing conditions for the video diffusion model. The video diffusion model will render the MLLM-generated conditions to the pixel space for diverse tasks, including video editing (add/remove/change), video grounding, and video reasoning segmentation with questions. We only apply diffusion loss for the whole pipeline training.

[Grounding] Could you label the bear in these video frames with red color masks?

[Addition] Add many fish around the woman

[Change] Replace the train with cupcakes and the ground with a table

[Removal] Please remove the man in black in given video frames.

[Change] Replace golden building with a white mountain.

[Env] Make it beside the sea.

[Removal] Please remove the man in given video frames.

[Reasoning] What object might be taken if the woman is thirsty? Highlight your answer with red masks.

[Style] make it Chinese ink style

[Color] Make the rhinocero furry

[Addition] Please add a ball in the given video frames.

[Grounding] Could you locate the cup in these video frames with red color masks?

[Grounding] Could you label the woman's clothes in these video frames with red color masks?

[Color] Make the girl in a pink shirt

[Style] make it in Monochrome Sketch Style.

[Addition] Please add boys in the video.

[Style] make it in Van Gogh Style.

[Addition] Add blooming flowers to the mountain trail
[Removal] Please remove the man in black in given video frames.

[Change] change the woman to a bear.

[Color] Make the swan white

[Addition] Please add a hat in the given video frames.

[Env] Make it on the beach.

[Style] Make it oil painting style

[Env] Make it raining, and add falling raindrops on the large rocks in the forest

[Style] make it in Japanese ukiyo e Style.

[Removal] remove the woman.

[Reasoning] Which is the tallest building? highlight your answer with red masks.

[Reasoning] Who runs faster? highlight your answer with red masks.

[Change] replace the cow with a horse.

[Addition] add a sunglass on her face.

[Removal] Please remove the woman in the video.

[Change] Change the food to a birthday cake.

[Grounding] Could you label the woman in these video frames with red color masks?

[Grounding] Could you label the walrus in these video frames with red color masks?

[Env] Make it rainy.

[Color] Change the milk to black coffee.

[Addition] Please add more buildings beside the road in the given video frames.

[Change] change the bowl to pizza.

[Grounding] Could you highlight the zebra in these video frames with red color masks?
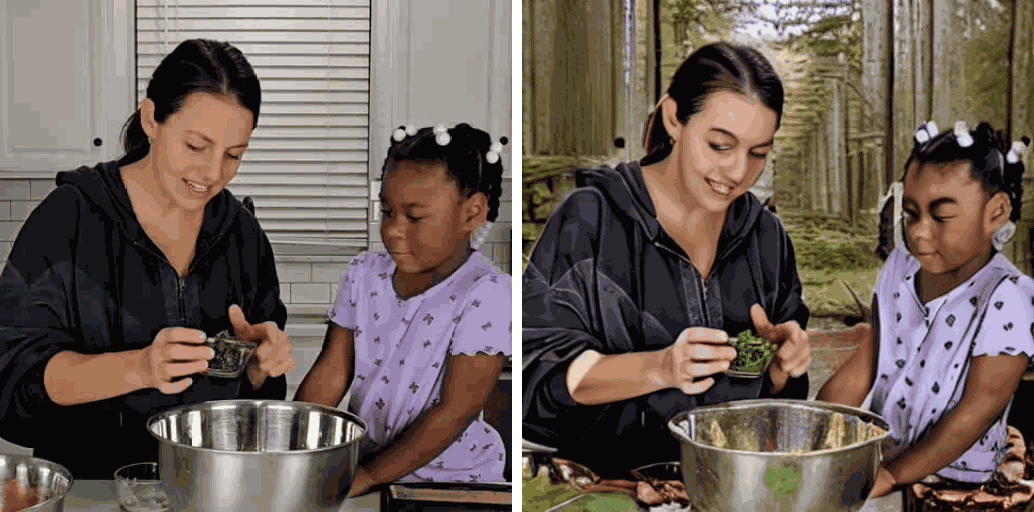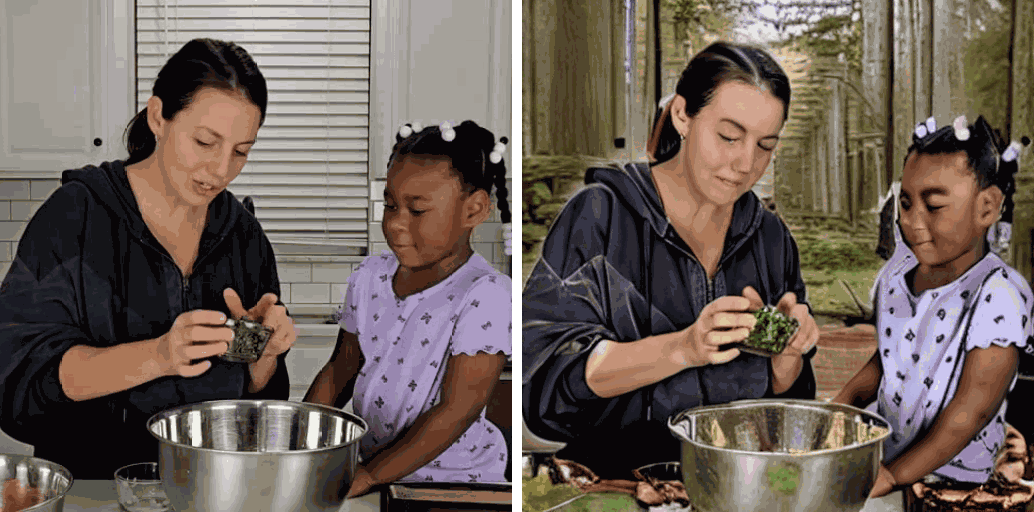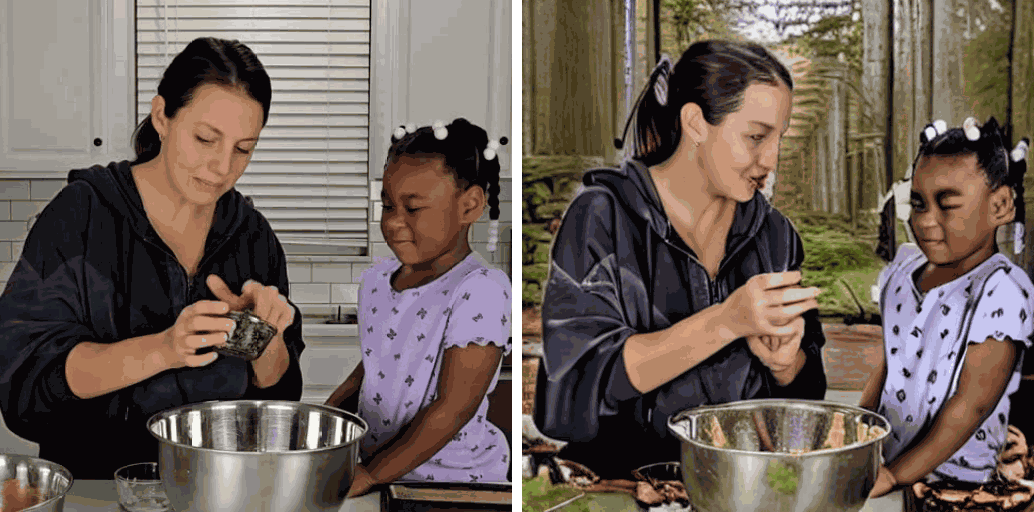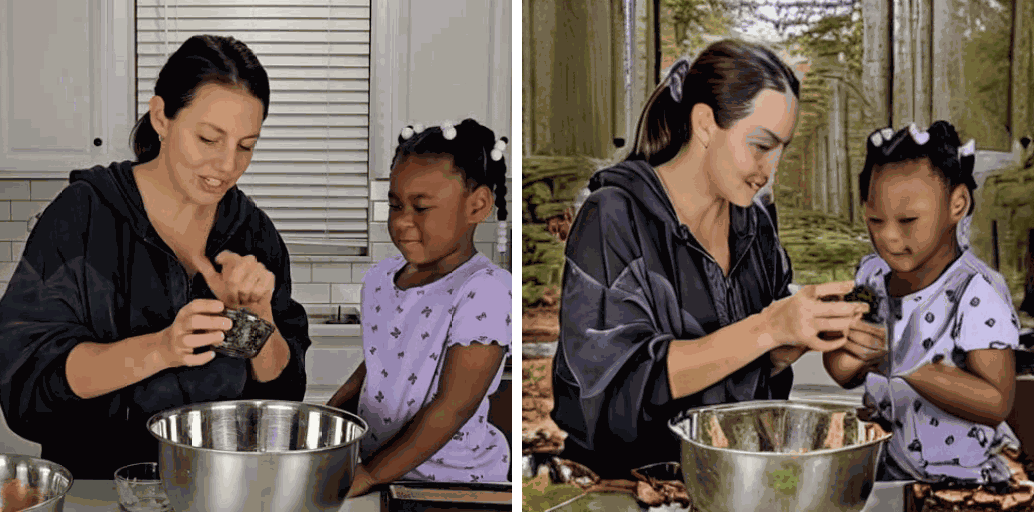
[Env] change it in the forest.

[Color] Make him looks like White Ancient Greek Sculpture.

[Change] Replace the cup with a bottle of flower.

[Removal] Please remove the car in the video.

[Style] Make it Cartoon style

[Addition] Add a flying giant seagull over the sea surface
[Style] Make it oil painting style

[Reasoning] What can be used to maintain the food? label your answer using red colored masks.

[Change] Replace the person with the Ironman

[Color] Make the bear red.

[Reasoning] What can be used for heating food? highlight your answer with red masks.

[Grounding] Please locate the laptop across video frames and use blue masks to mark them.

[Env] Replace the background with the desert
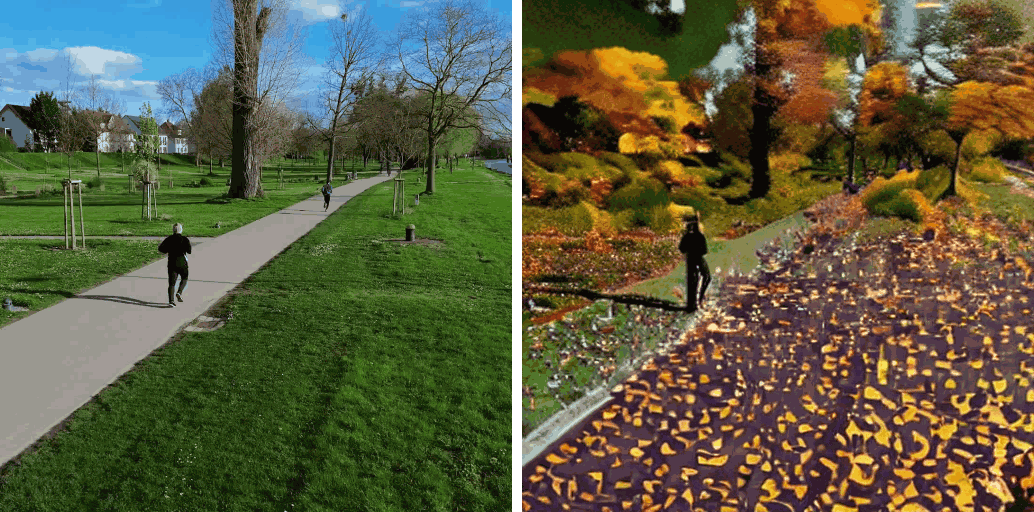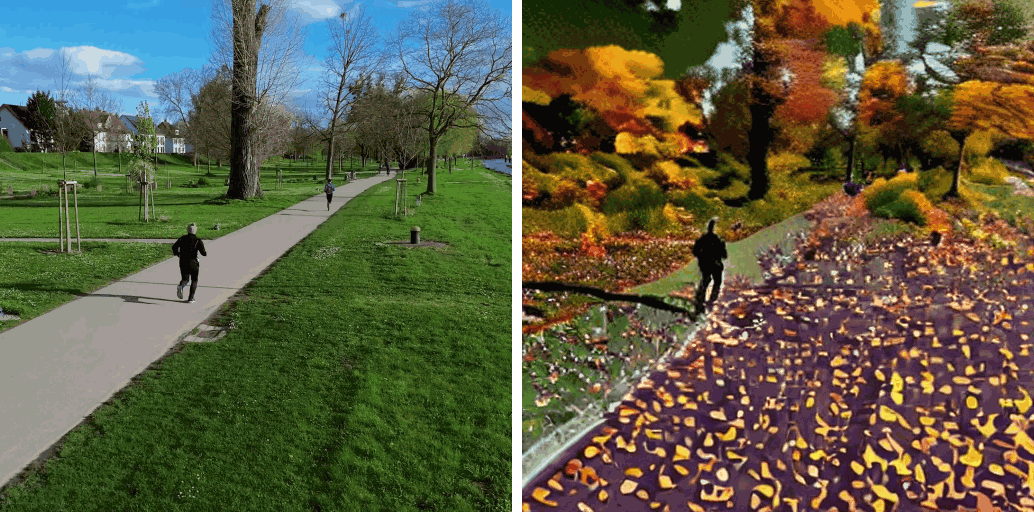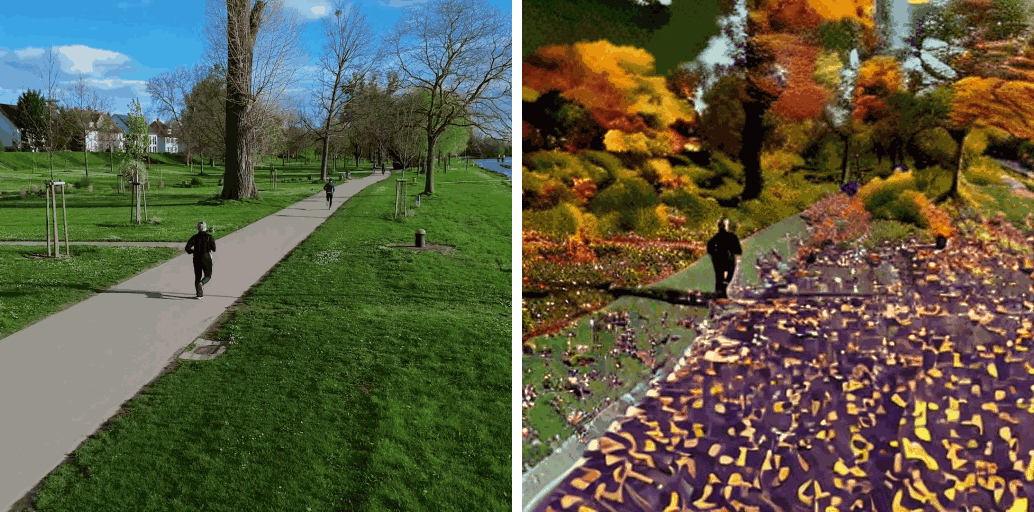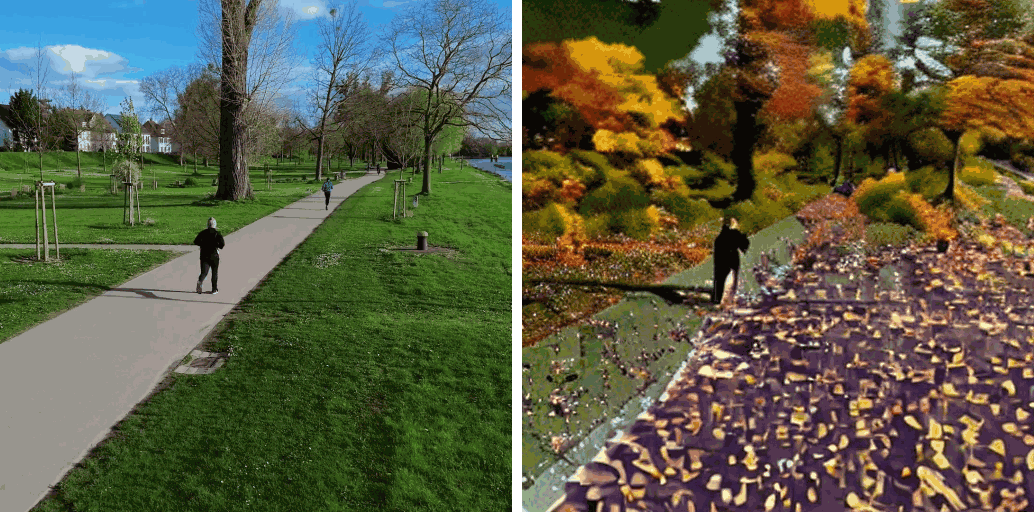
[Env] Make it autumn.

Reference Image

Input Video

Output Video
Instruction: Transfer the style in the reference image.

Reference Image

Input Video

Output Video
Instruction: Add the object in the reference image on the women.

Input1

Demo1

Input2

Demo2

Input Video

VEGGIE Output Video

Input1

Demo1

Input2

Demo2

Input Video

VEGGIE Output Video
*:Non-Instructional methods utilize paired video captions for editing.
Input Video

VEGGIE

VidToMe*

TokenFlow*

Flatten*

InstructDiff

LGVI

InsV2V

Instruction: Make it on the beach.
Input Video

VEGGIE

VidToMe*

TokenFlow*

Flatten*

InstructDiff

LGVI

InsV2V

Instruction: Please add a ball in the given video frames.
Input Video

VEGGIE

VidToMe*

TokenFlow*

Flatten*

InstructDiff

LGVI

InsV2V

Instruction: Make it chinese ink style.
Input Video

VEGGIE

VidToMe*

TokenFlow*

Flatten*

InstructDiff

LGVI

InsV2V

Instruction: Could you label the bear in these video frames with red color masks?
Input Video

VEGGIE

VidToMe*

TokenFlow*

Flatten*

InstructDiff

LGVI

InsV2V

Instruction: Replace the cup with a bottle of flower.
Input Video

VEGGIE

VidToMe*

TokenFlow*

Flatten*

InstructDiff

LGVI

InsV2V

Instruction: Please remove the man in black in given video frames.
Input Video

VEGGIE

VidToMe*

TokenFlow*

Flatten*

InstructDiff

LGVI
InsV2V

Instruction: Make the swan white.
Input Video

VEGGIE

VidToMe*

TokenFlow*
Flatten*
InstructDiff

LGVI
InsV2V

Instruction: What can be used for heating food? highlight your answer with red masks.
Original

Edited

Original

Edited

Original

Edited

Original

Edited

Original

Edited

Original

Edited

Original

Edited

Original

Edited

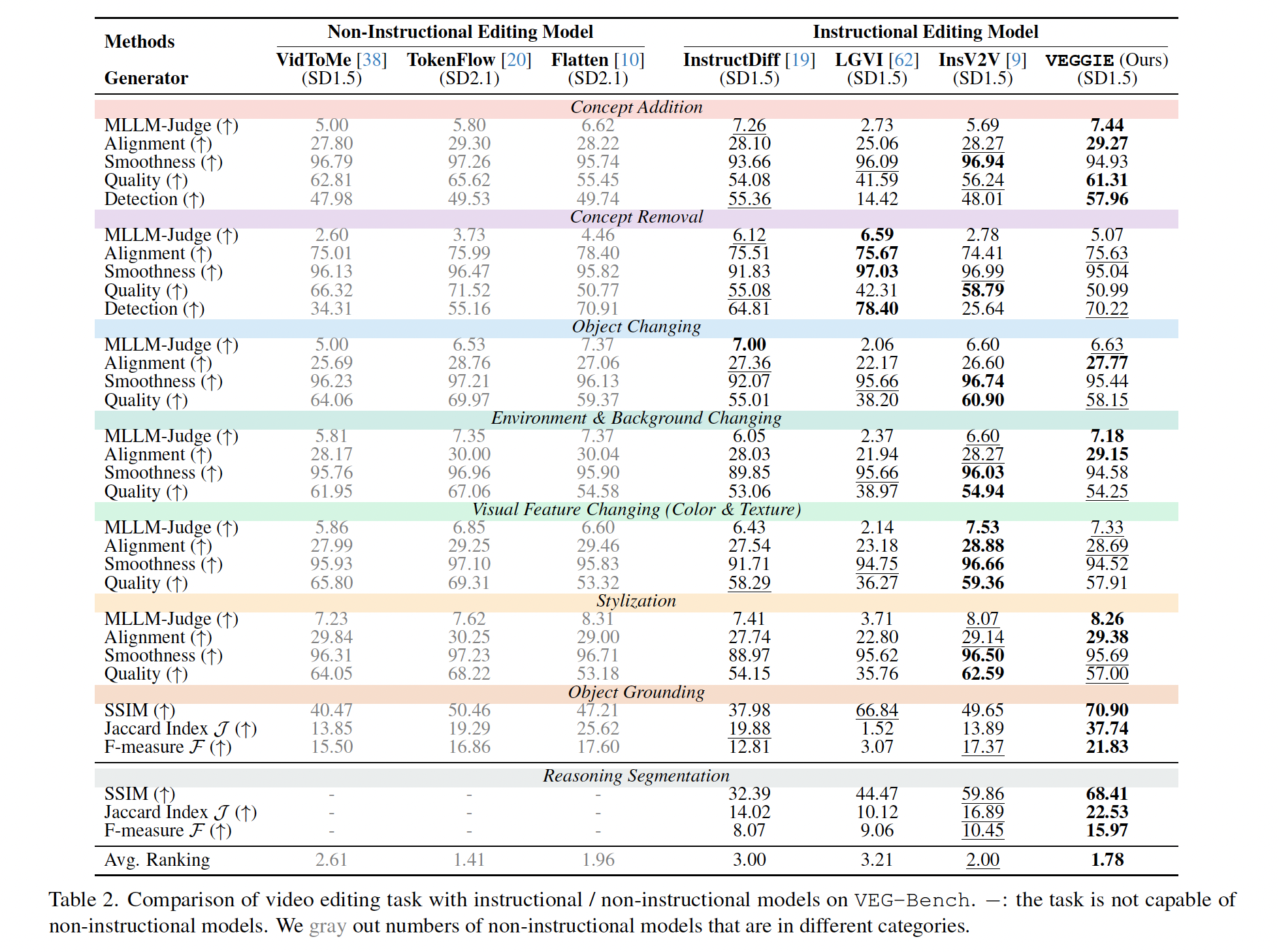
we evaluate 7 different models on VEG-Bench across 8 distinct editing skills. Overall, VEGGIE demonstrates the best performance among instructional video editing models. Compared to VEGGIE, non-instructional models often struggle with concept removal and addition. This limitation arises because these models rely on attention control or additional conditions (e.g., depth maps) that impose strong priors, constraining the model and making object addition or removal challenging. We also observe that InsV2V achieves high scores in quality and smoothness metrics, but underperforms in alignment and MLLM judgment, which demand faithful semantic changes. InsV2V often makes minimal changes to the input video, resulting in high video quality but unfaithful outputs. In contrast, VEGGIE strikes a better balance, delivering both high-quality visuals and accurate semantic alignment with the intended edits.
@article{yu2025veggie,
title={VEGGIE: Instructional Editing and Reasoning Video Concepts with Grounded Generation},
author={Shoubin Yu and Difan Liu and Ziqiao Ma and Yicong Hong and Yang Zhou and Hao Tan and Joyce Chai and Mohit Bansal},
year={2025},
journal={arXiv:2503.14350},
}